Datos abiertos del Gobierno de Aragón (II): Formato CSV como fuente de entrada en iReport



En este artículo, voy a poner un ejemplo de cómo consumir datos abiertos en formato JSON, convertirlos a formato CSV a través de una pequeña aplicación Java y utilizar directamente el fichero resultante como fuente de entrada en un informe realizado con iReport.
Como ejemplo ilustrativo, recurriremos a los datos que publica el Gobierno de Aragón en relación a las ayudas y subvenciones que publica.
Nota: Dado que en el post anterior, realizabamos un informe atacando contra un datasource de base de datos MySQL, variamos la fuente de entrada a ficheros CSV (para no aburrirnos y aprender algo más).
En primer lugar construimos una aplicación Java la cual lee los datos «Ayuda y Subvenciones del Gobierno de Aragón» en formato JSON (en esta página de la DGA está accesible el documento JSON ) y lo convierte a CVS.
Nota: Para la confección de la aplicación, hemos utilizado las librerías Google GSON 2.2.5 para leer el fichero JSON y SuperCSV para generar el fichero CSV.
Creamos el fichero Subvencion.java con los mismos atributos que los campos existentes en el formato JSON :
package org.neodoo.opendata;
public class Subvencion {
public String FechaPublicacion = null;
public String Seccion = null;
public String Subseccion = null;
public String Rango = null;
public String Emisor = null;
public String Titulo = null;
public String Texto = null;
public String UrlPdf = null;
public String getFechaPublicacion() {
return FechaPublicacion;
}
public void setFechaPublicacion(String fechaPublicacion) {
FechaPublicacion = fechaPublicacion;
}
public String getSeccion() {
return Seccion;
}
public void setSeccion(String seccion) {
Seccion = seccion;
}
public String getSubseccion() {
return Subseccion;
}
public void setSubseccion(String subseccion) {
Subseccion = subseccion;
}
public String getRango() {
return Rango;
}
public void setRango(String rango) {
Rango = rango;
}
public String getEmisor() {
return Emisor;
}
public void setEmisor(String emisor) {
Emisor = emisor;
}
public String getTitulo() {
return Titulo;
}
public void setTitulo(String titulo) {
Titulo = titulo;
}
public String getTexto() {
return Texto;
}
public void setTexto(String texto) {
Texto = texto;
}
public String getUrlPdf() {
return UrlPdf;
}
public void setUrlPdf(String urlPdf) {
UrlPdf = urlPdf;
}
}
El fichero DGALecturaJSON.java realiza una consulta a la URL que obtiene el archivo JSON y crea un fichero CSV en el sistema :
package org.neodoo.opendata;
import java.net.URL;
import java.util.List;
import java.nio.charset.Charset;
import java.io.FileWriter;
import java.io.IOException;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Type;
import java.net.MalformedURLException;
import org.supercsv.io.CsvBeanWriter;
import org.supercsv.io.ICsvBeanWriter;
import org.supercsv.prefs.CsvPreference;
import org.supercsv.cellprocessor.constraint.NotNull;
import org.supercsv.cellprocessor.ift.CellProcessor;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
public class DGALecturaJSON {
public static void main(String[] args) throws Exception {
// Obtenemos los objetos del fichero JSON
List subvenciones = getSubvenciones();
// Generamos el fichero CVS
writeWithCsvBeanWriter(subvenciones);
}
private static List getSubvenciones()
throws MalformedURLException, IOException {
List subvenciones = null;
Gson gson = new Gson();
// Llamamos a los datos en formato JSON de las convocatorias de ayudas y subvenciones del Gobierno de Aragón
// (disponible en http://opendata.aragon.es/catalogo/convocatorias-ayudas-subvenciones-gobierno-aragon)
String url = "http://www.boa.aragon.es/cgi-bin/EBOA/BRSCGI?CMD=VERLST&OUTPUTMODE=JSON&BASE=BOLE&DOCS=1-10000&SEC=OPENDATABOAJSON&SORT=-PUBL&SEPARADOR=&MATE-C=03CAS";
InputStream is = new URL(url).openStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,
Charset.forName("UTF-8")));
Type tipoListaSubvenciones = new TypeToken<List>() {
}.getType();
subvenciones = gson.fromJson(br, tipoListaSubvenciones);
return subvenciones;
}
public static void writeWithCsvBeanWriter(List subvenciones)
throws Exception {
ICsvBeanWriter beanWriter = null;
try {
beanWriter = new CsvBeanWriter(new FileWriter(
"target/dga_opendata_ayudas_y_subvenciones.csv"),
CsvPreference.STANDARD_PREFERENCE);
// Las cabeceras de las columnas
String[] header = new String[] { "FechaPublicacion", "Seccion",
"Subseccion", "Rango", "Emisor", "Titulo", "Texto",
"UrlPdf" };
CellProcessor[] processors = new CellProcessor[] { new NotNull(),
new NotNull(), new NotNull(), new NotNull(), new NotNull(),
new NotNull(), new NotNull(), new NotNull() };
// Escribimos la cabecera
beanWriter.writeHeader(header);
// Escribimos los objetos en el fichero
for (Subvencion customer : subvenciones) {
beanWriter.write(customer, header, processors);
}
} finally {
if (beanWriter != null) {
beanWriter.close();
}
}
}
}
Al ejecutar el programa anterior, se generará el archivo dga_ayudas_y_subvenciones.csv en el directorio target.
Nota: De forma similar al post anterior, podríamos volcar este fichero CSV en una base de datos MySQL y utilizar esta fuente de entrada para generar informes con iReport; sin embargo, prefiero poner un ejemplo de cómo consumir directamente un archivo CSV.
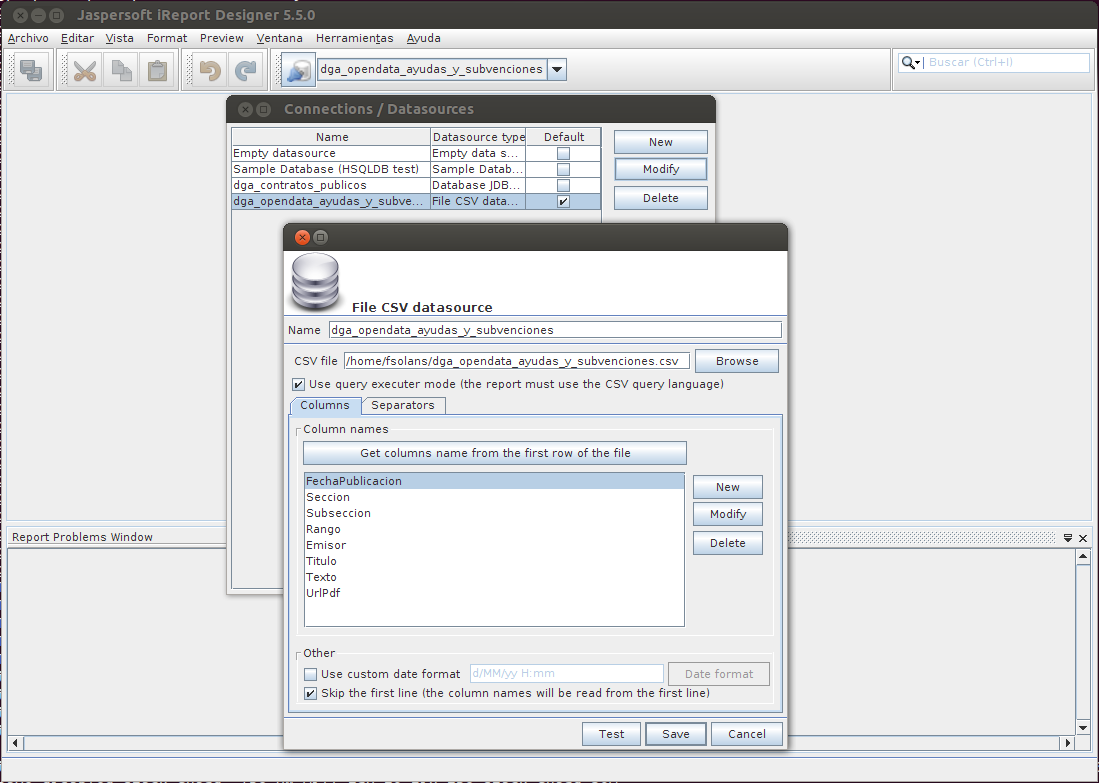
A continuación, abrimos la aplicación iReport y creamos la fuente de origen CSV seleccionando el fichero dga_ayudas_y_subvenciones.csv :
A continuación, ya podemos proceder a crear el informe utilizando este datasource.
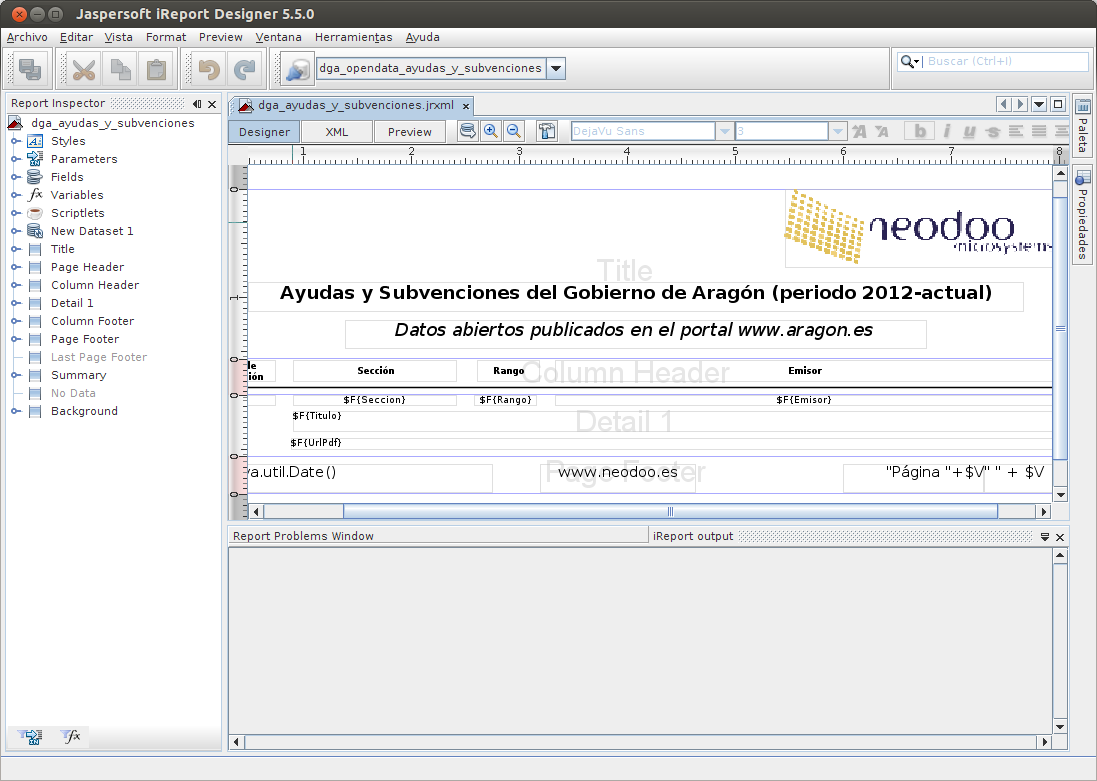
Dado que la creación del informe no aporta nada en especial, os dejo los siguientes elementos:
- La plantilla dga_ayudas_y_subvenciones.jrxml con las ayudas de la DGA desde 2012 hasta la fecha actual.
- Nota: Si queréis ver el PDF resultante, os lo podéis descargar directamente de aquí.
Desconozco el motivo pero aunque en teoría es factible, no he sido capaz de realizar el ejemplo utilizando un datasource del tipo JSON; no obstante, podemos comprobar las posibilidades de explotación de diversas fuentes de entrada.
Tips, tutoriales y novedades
Recibe directamente en tu correo todas las novedades, tips y tutoriales gratuitos que compartimos desde Neodoo Microsystems
0 comentarios